很多人看到医学新闻、营养宣传或教育研究时,都会遇到随机对照试验这个词。它之所以重要,不是因为名字专业,而是因为它能用随机分组和对照比较,更可靠地判断一种方法到底是否真正有效。
随机对照试验是什么意思?先用一句话讲明白
随机对照试验,英文简称 RCT(Randomized Controlled Trial),是一种把参与者随机分配到不同组,再比较不同干预效果的研究方法。
你只要记住三个词就够了:随机、对照、试验。

什么是“随机”?
“随机”不是随便分,而是通过抽签、随机数字表、计算机随机序列等方法分组,尽量避免研究者按主观意愿挑人。
这样做的核心价值,是降低选择偏差。如果某一组恰好年轻人更多、基础状态更好,结果就可能被扭曲;而随机化的目标,就是尽量让两组站在接近的起点上。
什么是“对照”?
“对照”就是要有一个可比较的参照组。没有对照组,很多变化看起来像干预有效,实际上可能只是自然波动。
比如一种改善睡眠的方法实施两周后,参与者感觉状态变好,这未必全是方法本身带来的效果,也可能与作息调整、心理预期或环境变化有关。只有同时设置对照组,比较才更有意义。
什么是“试验”?
“试验”意味着研究者会主动安排干预,并且提前设定流程、指标和观察时间,而不是只做普通观察。
这也是随机对照试验与日常经验判断最大的区别:它不是“看起来有用”,而是尝试用更规范的方式验证“到底有没有用”。
一个生活化场景:为什么 RCT 比“试了觉得不错”更可信

假设一所学校想验证:“每天背20个单词+听录音”,是否比单纯背单词更能提升记忆效果。
如果老师只挑基础好的学生去听录音组,最后成绩更高,其实无法证明方法本身更有效。因为起点就不公平。
更合理的做法是:
- 把学生随机分组
- A组只背单词
- B组背单词并听录音
- 在相同学习时长、相同测试时间、相同评分标准下比较结果
高质量证据,不只看结果好不好,更要看比较是否公平、过程是否透明。
这正是随机对照试验最核心的价值。
随机对照试验为什么被称为“金标准”?
随机对照试验常被称为证据金标准,主要因为它更擅长减少偏差,并帮助研究者更接近因果判断。
1. 随机分组降低混杂因素影响
研究中最常见的问题,是两组人原本就不一样。年龄、病情轻重、生活方式、教育程度,都可能影响结果。
随机化的目标,就是把这些已知和未知差异尽量打散。这样最终观察到的差别,更可能来自干预本身。
2. 对照组让“真实差异”更清楚
没有对照组,就很难区分:到底是干预有效,还是情况本来就会改善。
像感冒、焦虑、睡眠质量、学习状态这类指标,本身就会随时间自然波动。设置对照组后,研究者才能更清楚地看到干预是否真的带来了额外改善。
3. 盲法减少主观影响
盲法指的是让参与者、研究人员或结果评估者,不知道分组情况。
常见的情况包括:
- 单盲:参与者不知道自己在哪组
- 双盲:参与者和研究者都不知道分组
盲法的重要性在于,它能减少预期效应和观察者偏差。在药物、心理干预和症状评分研究中,这一点尤其关键。
4. 统计分析帮助判断差异是否可靠
随机对照试验不仅是“谁高谁低”的表面比较,还要结合统计分析判断差异是否可能由偶然造成。
这意味着,一项结论是否可信,不能只看结果方向,还要看样本量、置信区间、显著性水平、效应量等客观指标。
核心特点一表看懂
| 核心特点 | 主要作用 |
|---|---|
| 随机化 | 减少已知和未知因素干扰 |
| 对照组 | 提供公平比较基准 |
| 盲法 | 降低主观偏差 |
| 预设结局指标 | 提高结果解释的一致性 |
| 统计分析 | 判断差异是否超出偶然波动 |
随机对照试验的基本流程是什么?
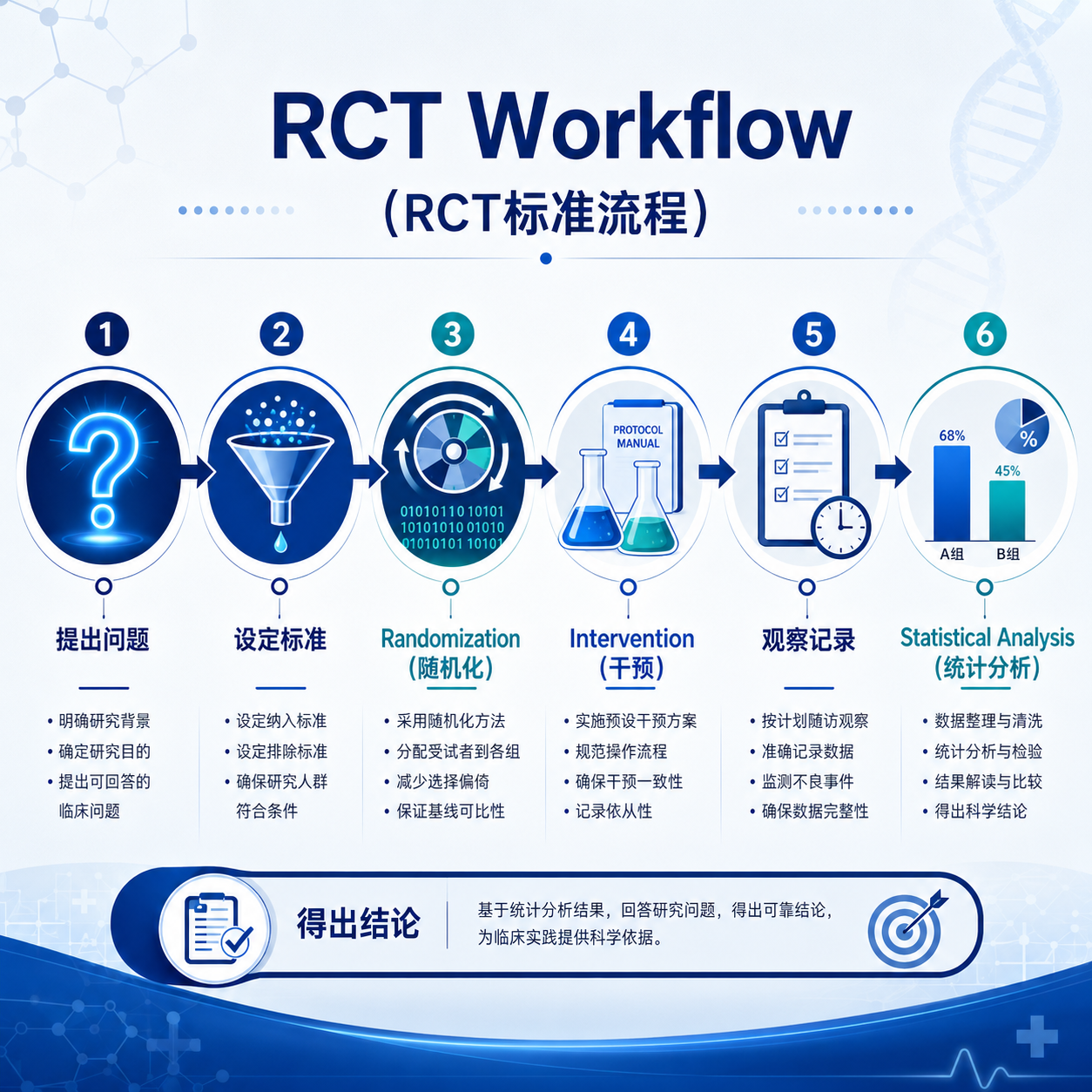
一项规范的随机对照试验,通常会按照清晰步骤进行。流程越规范,结果通常越值得参考。
1. 明确研究问题
研究开始前,团队要先定义一个具体问题,例如:
- 某种药物能否缩短发热持续时间?
- 某种学习方法能否提高测试成绩?
- 某种训练计划能否改善焦虑评分?
问题越明确,后续设计越容易控制偏差。
2. 设定纳入和排除标准
研究者需要明确谁可以参加、谁不适合参加。
这样做有两个作用:
- 保证样本具有一定一致性
- 降低不必要的干扰因素
3. 随机分组
这是 RCT 最关键的一步。常见做法包括计算机随机序列、区组随机、分层随机等。
如果随机化方法不清楚,研究可信度就会明显下降。
4. 实施干预
实验组和对照组接受不同安排,但除了核心干预外,其他条件应尽量保持一致,例如:
- 观察周期一致
- 评估时间点一致
- 记录方式一致
- 环境条件尽量一致
5. 观察并记录结果
研究通常会预先设定:
- 主要结局指标
- 次要结局指标
- 安全性指标
如果中途有人退出,也应记录脱落人数和原因,因为失访率会直接影响结果解释。
6. 数据分析与结论解释
最后,研究团队会比较两组结果,并评估:
- 差异是否明显
- 差异是否可能只是偶然
- 结果是否具有实际意义
- 研究过程中是否存在明显偏差
提出问题 → 选人 → 随机化 → 干预 → 观察 → 分析
这是理解随机对照试验最实用的一条主线。
随机对照试验有哪些常见类型?
不同研究问题,对应的 RCT 设计也不同。下面是最常见的几类。
平行组随机对照试验
最常见的一种设计。参与者被随机分到两组或多组,各组在同一时期接受不同干预。
适用于大多数药物、训练方法和教育干预研究。
交叉随机对照试验
同一批参与者会先后接受不同干预,相当于每个人都做自己的对照。
它的优点是节省样本量,但如果前一个干预影响持续太久,就会产生残留效应。
集群随机对照试验
随机分组单位不是个人,而是学校、医院、社区、班级等群体。
这种设计常用于公共卫生、教育政策和群体行为研究。
双盲随机对照试验
参与者和研究者都不知道分组情况。
在药物研究中,双盲设计通常能更有效减少预期偏差,因此被广泛视为更严格的形式。
安慰剂对照试验
对照组接受一种外观相似但没有有效成分的处理,用于排除心理期待带来的影响。
常见类型对比
| 类型 | 简单解释 | 常见应用 |
|---|---|---|
| 平行组试验 | 不同组同时接受不同干预 | 药物、行为干预 |
| 交叉试验 | 同一批人先后接受不同干预 | 小样本研究 |
| 集群试验 | 按学校、医院、社区分组 | 公共卫生、教育 |
| 双盲试验 | 参与者和研究者都不知道分组 | 药物研究 |
| 安慰剂对照 | 对照组接受无效模拟处理 | 疗效验证 |
随机对照试验和观察性研究有什么区别?
这两个概念经常被一起提到,但它们的核心差异非常明确:是否由研究者主动随机分配干预。
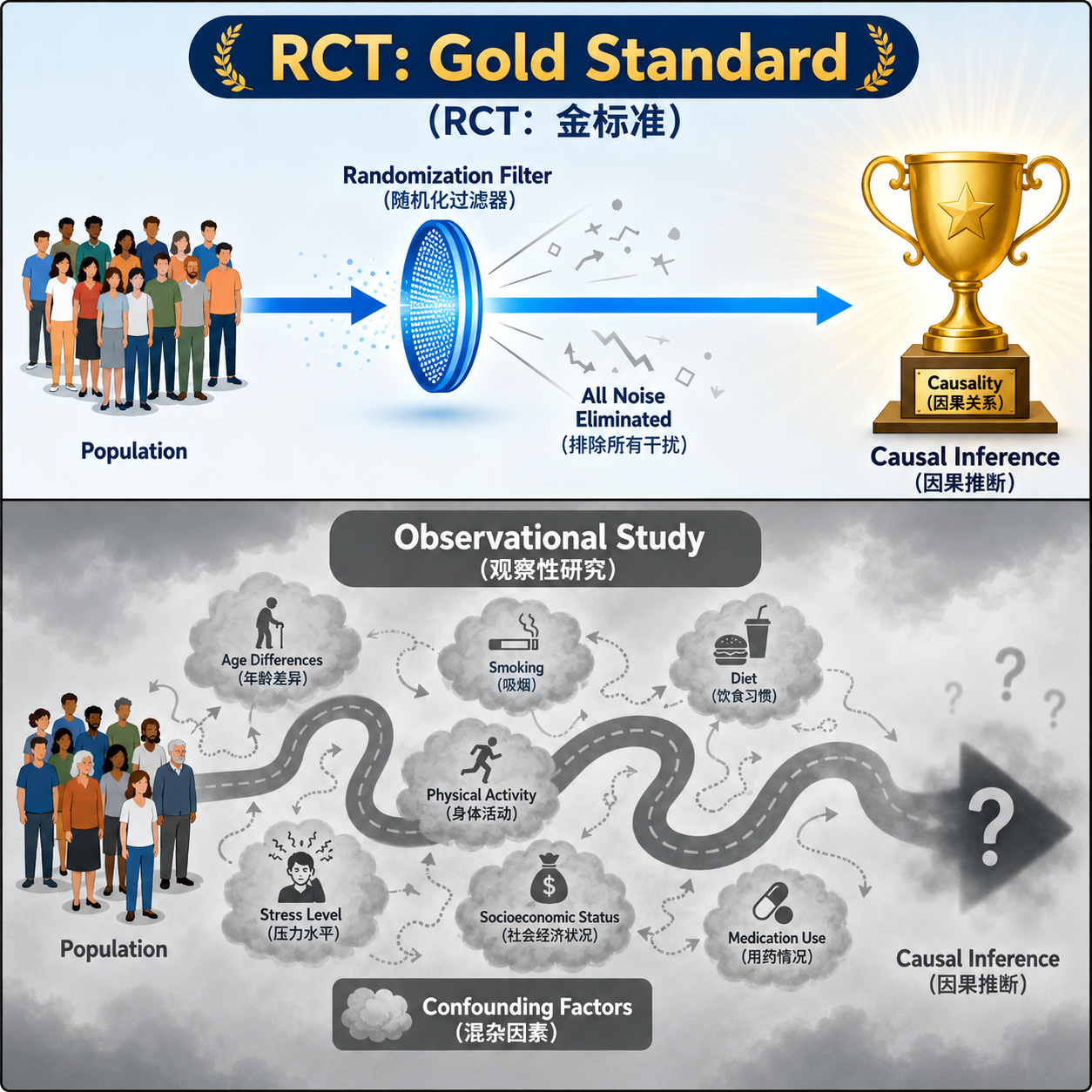
随机对照试验:主动安排干预
在随机对照试验中,研究者主动设计比较条件,因此更容易控制偏差,也更有机会做出因果推断。
观察性研究:观察现实中已发生的情况
观察性研究通常不干预现实,只记录自然状态下的差异。
它的优势是:
- 更接近真实世界
- 成本通常更低
- 研究启动更快
但缺点也明显:更容易受到混杂因素影响。
两者对比一眼看懂
| 比较项 | 随机对照试验 | 观察性研究 |
|---|---|---|
| 分组方式 | 随机分配 | 不随机 |
| 因果判断能力 | 较强 | 相对较弱 |
| 偏差控制 | 较好 | 更易受混杂影响 |
| 成本 | 通常较高 | 通常较低 |
| 速度 | 通常较慢 | 通常较快 |
如何判断一项随机对照试验是否可靠?
不是所有写着“RCT”的研究都同样可信。判断时,可以先看下面几个关键点。
快速判断清单
- 是否说明随机方法:如计算机随机序列、随机数字表
- 是否有合理对照组:对照条件是否可比
- 是否使用盲法:尤其是结果易受主观影响时
- 样本量是否足够:小样本结果往往更不稳定
- 结局指标是否提前设定:避免事后挑选结果
- 是否报告失访和脱落:脱落过多会影响结论
- 统计方法是否透明:是否明确说明分析逻辑
- 是否公开资金来源和利益冲突:透明度越高越好
一个高频场景:为什么“看起来有效”不等于“证据可靠”?
很多人看新闻时最容易踩的坑,就是只看结论,不看方法。
例如某篇报道说,某种补充剂让疲劳感降低了 30%。这个数字看上去很吸引人,但如果研究只有 20 人样本、没有盲法、失访率高达 25%,那这个“30%”的参考价值就会大幅下降。
结果再漂亮,如果随机化、对照、盲法和样本量不过关,结论也可能站不住。
因此,判断 RCT 可靠性,重点从来不只是“结果大不大”,而是研究设计是否扎实。
随机对照试验有哪些优点?
随机对照试验之所以重要,主要有以下几个优势:
- 更适合判断干预是否真正有效
- 能减少人为误差和选择偏差
- 研究路径清晰,逻辑更完整
- 更容易被临床指南和系统综述采纳
- 在证据分级体系中通常处于较高位置
如果研究目标是回答“这个方法有没有用”,高质量随机对照试验通常是非常有力的工具。
随机对照试验有哪些缺点和局限?
即便被称为“金标准”,RCT 也不是万能方法。它的局限同样需要看清。
1. 成本高
一项规范 RCT 往往需要:
- 招募受试者
- 组织干预执行
- 数据管理
- 随访与统计分析
这些步骤都会显著增加研究成本。
2. 周期长
从方案设计、伦理审查到随访结束,很多试验需要数月甚至数年。
3. 执行复杂
随机化、分配隐藏、盲法实施、统一记录、失访管理,每一步都需要高执行质量。
4. 存在伦理限制
有些问题不能随机分配。例如,不能为了研究危害而主动让一组人长期暴露在高风险因素下。
5. 外部适用性可能有限
为了提高研究内部一致性,很多 RCT 会设置较严格的纳入标准。这会导致试验人群与现实世界全部人群之间存在差异。
局限一表看懂
| 局限 | 简单解释 |
|---|---|
| 成本高 | 人员、执行、数据管理投入大 |
| 周期长 | 招募、干预、随访都耗时 |
| 执行复杂 | 需要严格流程控制 |
| 伦理限制 | 并非所有问题都能随机化 |
| 推广性有限 | 结果未必完全代表全部真实人群 |
医学之外,随机对照试验还能用在哪些领域?
虽然 RCT 最常见于医学,但它的应用远不止于此。
教育研究
用于比较不同教学法、阅读训练、线上线下课程模式的效果。
心理学研究
用于评估认知训练、减压课程、行为疗法、睡眠干预等效果。
公共政策
用于评估补贴方式、提醒短信、就业培训、疫苗推广策略等是否有效。
行为科学与互联网测试
常见的 A/B 测试,本质上就具有很强的对照实验思维,例如比较两种页面设计对点击率或转化行为的影响。
一个更贴近企业的场景:为什么“对照思维”对产品测试也重要
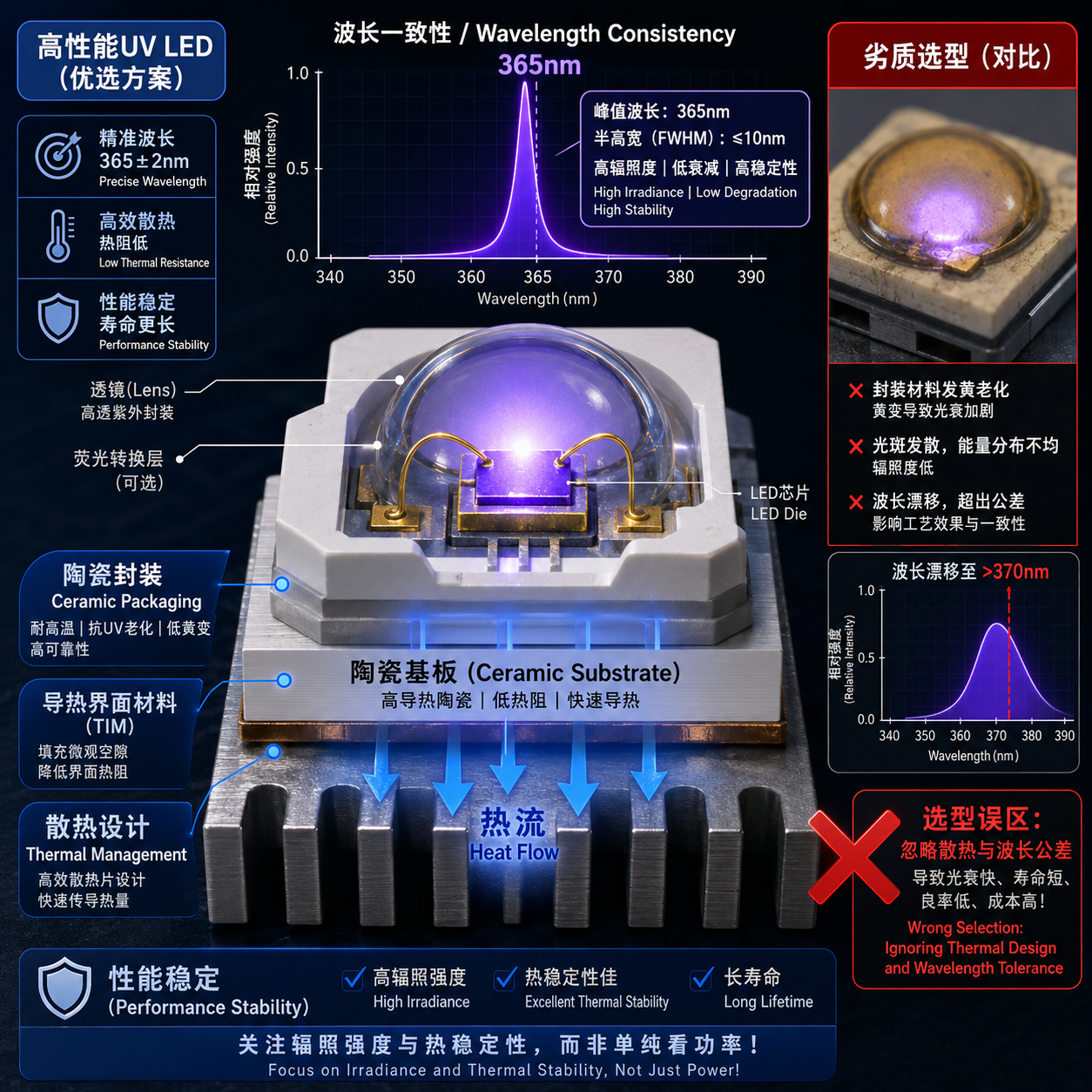
当企业要比较新材料和旧材料、新工艺和旧工艺、不同驱动条件下的稳定性时,如果测试条件不统一,结论就很容易失真。
比如在 LED 器件验证中,如果今天在一种散热条件下测亮度,明天换了供电方式再测寿命,然后把两次数据直接比较,这样的结果参考价值很低。
更合理的测试思路通常包括:
- 统一样本标准
- 保持相同供电和散热环境
- 提前设定评价指标
- 按固定时间点记录数据
- 保留对照样本做重复验证
这类方法不等同于医学 RCT,但在“公平比较”这件事上,逻辑是一致的。像恒彩电子这类涉及多规格、多功率段器件开发的制造场景,越是产品复杂,越需要这种可比较、可复现的验证思路。
关于随机对照试验,最常见的几个问题
随机对照试验是什么意思?
随机对照试验是一种把参与者随机分组,再比较不同干预效果的研究方法。它的核心是随机化、对照组和规范观察。
随机对照试验为什么是金标准?
因为它能更有效减少偏差,并提高因果判断的可信度,尤其适合回答“某种干预是否有效”这类问题。
随机对照试验和观察性研究有什么区别?
最大区别是是否随机分配干预。RCT 更适合判断因果,观察性研究更接近真实世界,但更容易受混杂因素影响。
随机对照试验一定比别的研究更好吗?
不一定。它在评估干预效果时通常更强,但成本高、周期长,而且并非所有问题都适合随机化。
随机对照试验有哪些缺点?
常见局限包括成本高、周期长、执行复杂、伦理限制、推广性有限。
什么是双盲随机对照试验?
指参与者和研究者都不知道分组情况,以减少主观期待和人为判断偏差。
如何快速判断一项随机对照试验是否靠谱?
重点看:
- 随机方法是否清楚
- 是否有合理对照组
- 是否使用盲法
- 样本量是否足够
- 是否报告脱落情况
- 研究是否透明公开
随机对照试验的思路能用于企业产品测试吗?
可以。虽然企业测试不一定完全照搬医学试验形式,但统一条件、设置对照、提前设定指标、持续记录数据、重复验证结果,都属于非常实用的科学比较思路。
随机对照试验中的样本量越大越好吗?
不一定。样本量过小会导致结果不稳定,但样本量过大也可能让临床意义很小的差异看起来“统计上显著”。关键不是越大越好,而是是否进行了合理的样本量估算。
没有双盲的随机对照试验就不可信吗?
也不一定。有些研究因为干预形式特殊,很难做到双盲,例如运动训练、手术方式或教学方法比较。这种情况下,要看研究是否采用了其他降低偏差的方法,例如盲法评估结果、统一流程、客观指标测量等。