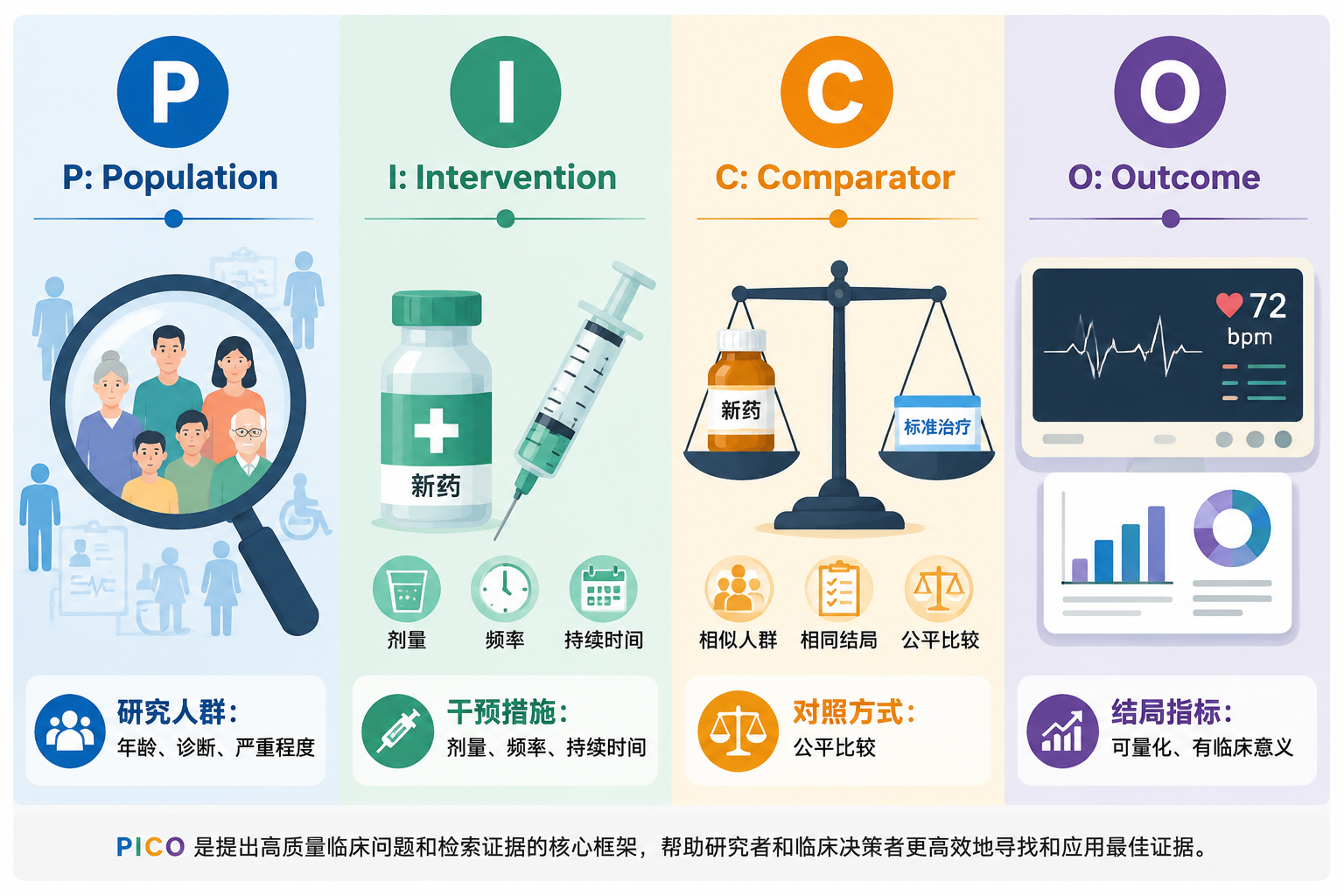
什么是 rct设计 pico?
如果你在设计随机对照试验时总觉得问题太大、入组标准难定、结局指标越写越散,那么问题往往不在统计,而在研究问题没有被清楚定义。rct设计 pico,本质上就是用 PICO 框架把 RCT 里的研究对象、干预措施、对照方式和结局指标写明确,让试验从一开始就更容易执行。
一个高质量的 RCT,通常不是从复杂统计开始,而是从一个可比较、可测量、可执行的问题开始。
简单说,PICO 就是把研究问题拆成四部分:
P(Population):研究人群
I(Intervention):干预措施
C(Comparator):对照方式
O(Outcome):结局指标
当这四项写清楚后,后续的入组标准、样本量估算、随机化方案、统计分析路径都会明显更顺。

为什么随机对照试验必须先写清 PICO
很多研究在立项阶段看起来方向正确,真正执行后却频繁返工。常见原因不是团队不专业,而是研究问题过宽,导致方案无法稳定落地。
例如,研究者最初只写“某疗法是否有效”,这类表述看似合理,实际会立刻带来几个问题:
研究对象是谁,不明确
干预如何执行,不具体
对照组选什么,不统一
最终看什么结果,不聚焦
一旦进入伦理、招募或数据分析阶段,这些模糊点就会被放大。
PICO 的价值,不是让题目更好看,而是让试验少走弯路。
从方法学上看,清晰的 PICO 至少会影响以下关键环节:
纳入与排除标准是否可执行
主要结局是否可以量化
对照组设置是否具有解释价值
样本量估算是否有基础参数
统计分析方法是否能提前确定
PICO 四个字母分别代表什么
P:Population,研究人群
P 回答的是“你研究谁”。
这一步不能只写疾病名称,更要写清研究边界。一个可执行的人群描述,通常包括:
年龄范围
疾病诊断标准
病情严重程度
纳入标准
排除标准
例如,“高血压患者”太宽,而“60—80 岁、确诊原发性高血压、近 3 个月病情稳定的门诊患者”就清楚得多。
人群定义越清楚,组内差异通常越小,结果解释也越稳定。反过来,如果把轻症、中症、重症全部混在一起,研究噪声会上升,样本量往往也会被动增加。
I:Intervention,干预措施
I 回答的是“你给了什么”。
在 RCT 中,干预不能只写名称,必须写到能被重复执行。通常至少需要包括:
干预类型
剂量或参数
频率
持续时间
执行方式
例如,“采用新药 X”不够,写成“每日口服新药 X 10 mg,连续 24 周”才具备可复制性。
如果是器械、康复训练或行为干预,同样要写清流程。不然不同研究中心执行方式不一致,结果就很难比较。
C:Comparator,对照方式
C 回答的是“你拿什么来比较”。
随机对照试验的核心不是看干预前后有没有变化,而是看与合理对照相比是否存在差异。常见对照方式包括:
安慰剂对照
标准治疗对照
传统方案对照
不同剂量对照
活性对照
这里最容易出问题的是“对照不匹配”。如果临床实际最关心的是新方案能否优于标准治疗,却拿一个明显偏弱的方案作对照,那么即便结果显著,研究价值也会被质疑。
O:Outcome,结局指标
O 回答的是“你最终看什么结果”。
结局指标最怕写虚。好的结局通常具有几个特征:
可量化
可重复测量
有临床意义
有明确时间点
例如,“患者感觉更舒服”通常不能单独作为主要结局;而“24 周后 HbA1c 下降至少 1% 的比例”就更稳,也更容易分析。
一个完整的 O 往往还要区分:
主要结局
次要结局
安全性结局
测量时间点
一个真实场景:为什么很多试验在立项时就埋下失败风险
设想一个很常见的场景:团队准备做一项降压新药研究,会议一开始的提法是“看看新药对老年患者有没有帮助”。
听起来方向没错,但一旦进入方案撰写,就会立刻卡住:老年是 60 岁以上还是 75 岁以上?已有基础治疗是否稳定?是和安慰剂比,还是和指南推荐标准药物比?主要看收缩压下降值,还是看心血管事件发生率?
如果这些问题不在前期收紧,后面通常会出现三类连锁问题:
招募标准反复修改,延长启动周期
研究中心理解不一致,执行偏差变大
结局定义过散,统计分析难以聚焦
很多试验不是败在实施阶段,而是败在问题定义阶段。
当研究者把问题改写为:
在 60—80 岁原发性高血压且近 3 个月用药稳定的患者中,相比标准降压治疗,每日使用新药 X 10 mg 是否能在 12 个月内 更显著降低收缩压?
整个项目的路径会突然清楚很多。谁能入组、干预怎么做、和谁比较、何时测结果,都有了明确边界。

rct设计 pico 的标准写法:从问题到方案的 6 步
第 1 步:先确定研究目标
先明确你到底想回答什么:
是比较疗效优于现有方案?
是验证不劣于标准治疗?
是观察风险降低还是症状改善?
目标不清,PICO 就会飘。尤其新手容易把一个研究同时写成疗效、安全性、生活质量、依从性全部都想看,最后反而主线不清。
第 2 步:把研究人群写到可招募
这一步建议至少明确:
年龄
诊断依据
病情分层
治疗背景
纳入/排除条件
如果别人读完你的 P 描述,还不知道该招哪些人,说明写得还不够。
第 3 步:把干预写到可复制
一个合格的 I,至少要让别的团队能按同样方式执行。重点包括:
干预名称
剂量或参数
使用频率
干预周期
操作流程
第 4 步:选择真正有意义的对照
对照组不是为了“凑一组”,而是为了回答研究问题。判断标准很简单:
这个对照能否代表当前常规实践?
这个比较结果能否支持真实决策?
这个设置是否公平、可解释?
第 5 步:把结局写到能测量、能分析
建议优先写清:
主要结局是什么
次要结局有哪些
安全性指标看什么
在哪个时间点测量
如果结局不能量化,统计分析就很难稳住。
第 6 步:把四项合成一句完整研究问题
最常用的句式是:
在【P】中,相比【C】,【I】是否能在【时间范围】内改善【O】?
这是最实用的写法,因为它既适合立项讨论,也能直接进入方案摘要。
完整案例:老年高血压研究怎么写出一个合格的 PICO
研究主题
研究新药 X 是否优于标准降压治疗。
P:研究人群
可写为:
60—80 岁
确诊原发性高血压
近 3 个月病情稳定
排除严重心衰、肝衰、肾衰患者
这样的定义能明显降低人群异质性,让结果更容易解释。
I:干预措施
可写为:
每日口服新药 X 10 mg
连续 12 个月
C:对照方式
可写为:
标准降压药治疗
用法按现行临床规范执行
同样随访 12 个月
O:结局指标
可以这样设置:
主要结局:12 个月后收缩压下降幅度
次要结局:心血管事件发生率
安全性结局:不良反应发生率
最终研究问题
在 60—80 岁原发性高血压患者中,相比标准降压治疗,每日口服新药 X 10 mg 是否能在 12 个月内 更显著降低收缩压,并减少心血管事件?
这个 PICO 的质量较高,原因主要有三点:
边界清楚:人群和时间范围都明确
比较合理:对照组选的是标准治疗
结局扎实:既有量化指标,也有临床事件和安全性观察
rct设计 pico 如何影响样本量、随机化和统计分析
很多人把 PICO 当成“写研究问题的工具”,但它的实际影响远不止于此。

对样本量估算的影响
样本量计算通常依赖以下信息:
主要结局类型
预期差异大小
组内变异程度
显著性水平与把握度
例如:
若主要结局是连续变量,如收缩压平均下降值,常按均值差进行估算
若主要结局是分类变量,如事件发生率,常按比例差进行估算
若主要结局是生存时间,则需要采用时间事件分析思路
同样一个主题,结局不同,样本量差异可能非常大。12 周血压下降值和2 年心血管事件率,后者往往需要更多样本。
对随机化方式的影响
如果 P 定义后发现研究对象差异较大,研究者通常会考虑:
分层随机
区组随机
按年龄、性别、病情严重程度等关键变量平衡分组
这些决策都不是试验后期再想,而是在 PICO 阶段就已经埋下基础。
对统计分析路径的影响
结局一旦明确,统计路径就会自然显现:
连续变量常见比较均值差
二分类结局常见比较风险比或比值比
生存结局常见使用Kaplan–Meier 曲线与Cox 回归
也就是说,PICO 写得越清楚,统计分析越不容易后期补救。
常见错误:新手最容易踩的 7 个坑
1. 人群写得太宽
例如“老年患者”“慢病患者”“术后患者”。这类描述边界过大,会显著提高样本异质性。
2. 干预写得太模糊
“综合治疗”“新方案”这类词看似完整,实际上无法重复执行。
3. 对照组选择没有现实意义
如果临床实际关注的是和标准治疗比较,却设置一个明显偏弱的对照,结果会失去解释价值。
4. 结局不可量化
“状态更好”“感觉改善”如果没有量表或指标支撑,很难作为主要结局。
5. 只盯统计显著,不看临床意义
例如某研究差异达到 P < 0.05,但平均改善幅度只有 1 mmHg,这未必足以改变治疗决策。
6. 没写时间点
“改善血压”不完整,“12 周后改善血压”才完整。没有时间边界,结局就缺少执行抓手。
7. 框架与研究问题不匹配
并非所有问题都适合 RCT。若研究的是长期暴露风险,如空气污染或夜班暴露,更适合用其他观察性研究框架。
一个高质量 PICO 应该满足哪些标准
一个合格的 rct设计 pico,通常至少满足以下 5 个标准:
明确:别人能一眼看懂你研究谁
可比较:干预与对照有公平比较基础
可测量:结局有量化方式和时间点
可执行:招募、随访和成本在现实中可落地
有实际意义:结果能支持真实决策,而不只是统计上显著
可以用下面这张清单快速自查:
[ ] 人群是否具体到能直接招募?
[ ] 干预是否写清剂量、频率和持续时间?
[ ] 对照是否符合临床或实际应用场景?
[ ] 主要结局是否可量化且有时间点?
[ ] 结果即便显著,是否也具备实际价值?
PICO、PICOS、PECO 有什么区别
这几个框架常被混用,但适用场景并不相同。
| 框架 | 适用场景 | 关键特点 |
|---|---|---|
| PICO | 干预研究、随机对照试验 | 聚焦人群、干预、对照、结局 |
| PICOS | 系统综述、文献筛选 | 多了 S = Study Design |
| PECO | 观察性研究、暴露研究 | 用 E = Exposure 替代干预 |
判断方法很简单:
如果你在做随机对照试验,通常优先用 PICO
如果你在做系统综述,往往需要 PICOS
如果你研究的是暴露与风险关系,更适合 PECO
非临床场景下,PICO 思路为什么仍然有价值
虽然 rct设计 pico 最常见于临床研究,但它背后的结构化思维也适用于很多研发与验证场景。
例如在器械验证、工业检测、机器视觉测试里,团队同样要回答四个问题:
测试对象是什么
采用什么方案
与什么基线或旧方案相比
用什么指标评价结果
一个常见场景是光学或检测方案评估。假如团队在比较不同波长光源对缺陷识别率的影响,如果测试对象不统一、曝光参数不固定、对照流程不明确、评价指标只写“更清晰”,那么结果很容易失真。
而当问题被改写为:在某类表面材质样品中,相比传统白光方案,采用特定波长光源是否能在固定曝光条件下提高缺陷检出率并降低误检率,整个测试逻辑就会明显扎实。这也是为什么像恒彩电子这类涉及医疗相关光源与工业检测场景的团队,往往也会强调可比较、可重复、可量化的测试设计原则。
rct设计 pico 实操模板
简洁版模板
在【P】中,相比【C】,【I】是否能改善【O】?
完整版模板
在【特定人群 P】中,相比【对照措施 C】,【干预措施 I】是否能在【时间范围】内改善【主要结局 O】?
填写版模板
研究人群(P):
干预措施(I):
对照方式(C):
主要结局(O):
次要结局:
安全性结局:
测量时间点:
最终研究问题:
常见问题
RCT 为什么要先写 PICO?
因为 PICO 能先把研究边界确定下来。边界一清楚,后续的招募、对照组设置、样本量估算、统计分析才不会反复返工。
一个好的 rct设计 pico 应该包含什么?
至少要包含:明确的人群、具体的干预、合理的对照、可量化的结局,以及清楚的时间范围。
PICO 能不能用于非 RCT 研究?
可以,但不一定总是最合适。若研究的是暴露因素与风险关系,通常更适合使用 PECO;若用于系统综述筛选文献,往往要扩展为 PICOS。
PICO 如何帮助样本量估算?
因为样本量计算依赖主要结局类型、预期差异大小、组内变异程度和随访时间。这些核心信息都来自一个写清楚的 PICO。
统计显著就代表临床有意义吗?
不一定。统计显著说明差异可能不是随机产生,但并不自动等于实际意义足够大。因此,设计结局时既要考虑可分析,也要考虑是否值得改变实践。
新手写 PICO 时最该优先盯住什么?
优先盯住两点:人群是否足够清楚,以及结局是否能明确测量。这两项一旦模糊,后面的干预、对照和统计通常都会跟着变乱。
PICO 写完后,怎样判断是否还能继续优化?
最直接的方法是反问自己:别人是否能只看这一句话,就明白研究谁、比什么、看什么、何时看。如果答案是否定的,就说明还需要继续收紧。
rct设计 pico 不是形式化写作,而是随机对照试验能否做稳的起点。只要把 P、I、C、O 四个部分写到明确、可比较、可测量、可执行,试验后续的招募、随机化、样本量估算和统计分析都会更顺。
对新手而言,最值得投入时间的,不是一开始追求复杂方案,而是先把问题定义正确。一个清楚的 PICO,往往比一页模糊目标更有研究价值。